
Google doesn’t have the best track record when it comes to creating AI images.
In February, the image generator built into Gemini, Google’s AI chatbot, was found to have randomly inserted racial and ethnic diversity into messages about people, resulting in images of racially diverse Nazis, among other offensive inaccuracies.
Google pulled the generator, promising to improve it and eventually re-release it. As we await its return, the company is launching an improved image creation tool, Imagen 2, within its Vertex AI developer platform — albeit one with a decidedly more business bent. Google announced Imagen 2 at its annual Cloud Next conference in Las Vegas.
Image Credits: Frederic Lardinois/TechCrunch
Imagen 2 — which is actually a family of models, released in December after being previewed at Google’s I/O conference in May 2023 — can create and edit images with a text message, like DALL-E and OpenAI’s Midjourney. Of interest to corporate types, Imagen 2 can render text, emblems and logos in multiple languages, optionally overlaying these elements onto existing images — for example, business cards, apparel and products.
After first launching in preview, image editing with Imagen 2 is now generally available in Vertex AI along with two new features: inpainting and outpainting. Inpainting and outpainting, features that other popular image generators like DALL-E have been offering for some time, can be used to remove unwanted parts of an image, add new elements and extend the boundaries of an image to create a wider field of view.
But the real meat of the Imagen 2 upgrade is what Google calls “text-to-live images.”
Imagen 2 can now create short four-second videos from text messages, according to AI-powered clip-making tools like Runway, Pika, and Irreverent Labs. True to Imagen 2’s enterprise focus, Google presents Live Images as a tool for marketers and creatives, such as a GIF maker for ads featuring nature, food, and animals — something Imagen 2 has improved upon.
Google says Live Images can capture “a range of camera angles and movements” while “supporting consistency throughout the series.” But it’s at low resolution for now: 360 pixels by 640 pixels. Google promises that this will improve in the future.
To assuage (or at least try to assuage) concerns about the possibility of deepfakes, Google says Imagen 2 will use SynthID, an approach developed by Google DeepMind, to apply invisible, cryptographic watermarks to live pictures. Of course, detecting these watermarks—which Google claims are resistant to modifications, including compression, filters, and color tone adjustments—requires a tool provided by Google that isn’t available from third parties.
And no doubt keen to avoid another media controversy, Google is stressing that generations of live images will be “filtered for safety”. A spokesperson told TechCrunch via email: “The The Imagen 2 model in Vertex AI did not experience the same problems as the Gemini application. We continue to test extensively and engage with our customers.”
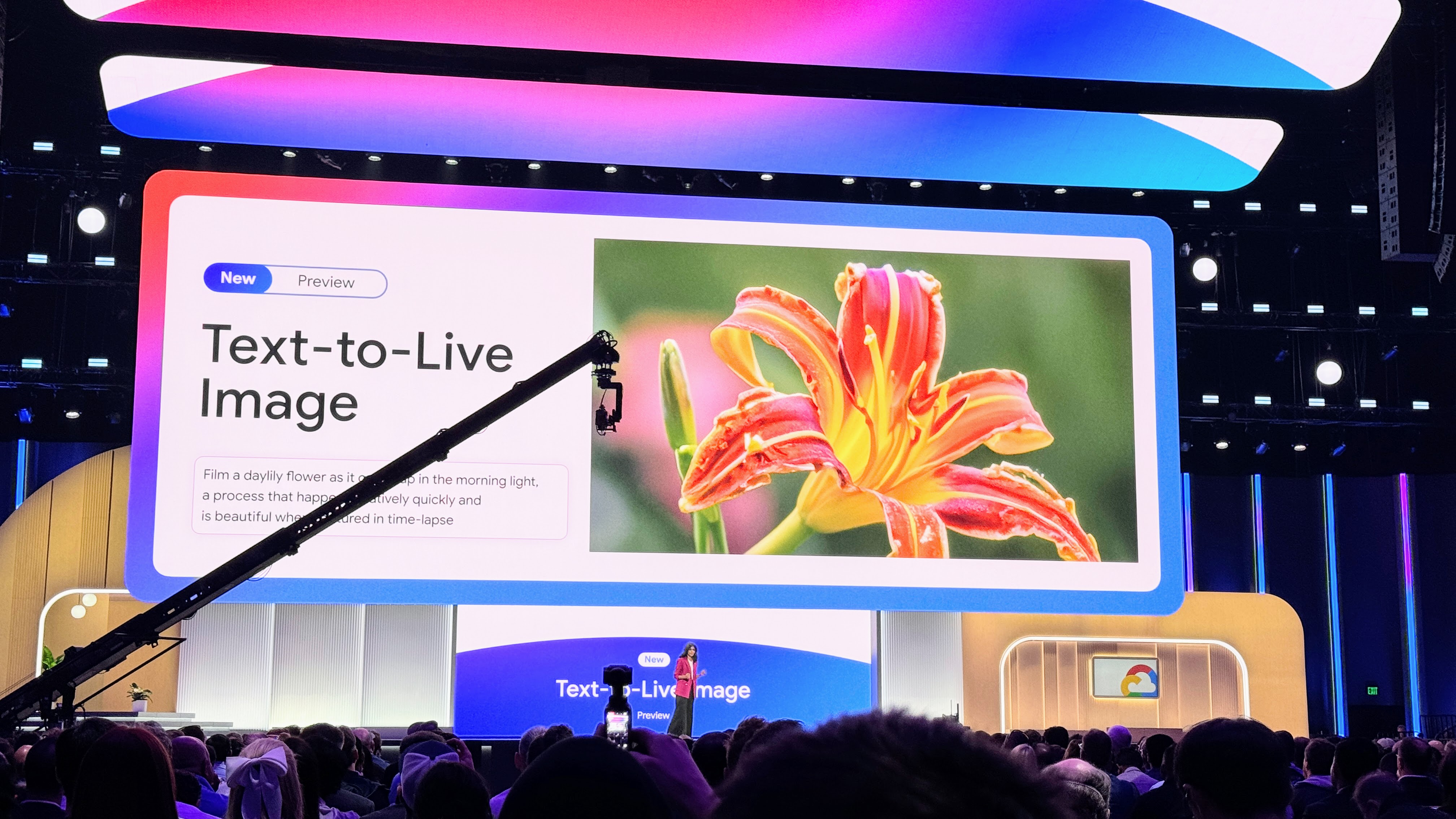
Image Credits: Frederic Lardinois/TechCrunch
But if we generously assume for a moment that Google’s watermarking technology, mitigations and filters are as effective as they claim, they’re even live images competitive with existing video creation tools?
Not really.
Runway can create 18-second clips at much higher resolutions. Stability AI’s video clip tool, Stable Video Diffusion, offers more customizability (in terms of frame rate). And OpenAI’s Sora — which, of course, isn’t commercially available yet — looks poised to blow away the competition with the photorealism it can achieve.
So what are the real technical advantages of live images? I’m not really sure. And I don’t think I’m too harsh.
After all, Google is behind some really impressive video production technology like Imagen Video and Phenaki. Phenaki, one of Google’s more interesting experiments in text-to-video conversion, turns long, detailed prompts into two-minute-plus “movies” — with the caveat that the clips are low-resolution, low-frame-rate, and only somewhat coherent.
In light of recent reports suggesting that the generative AI revolution has caught up with Google CEO Sundar Pichai and that the company is still struggling to keep pace with competitors, it’s not surprising that a product like Live Images has the feel of also running. However, it is disappointing. I can’t help but feel that there is – or was – a more impressive product lurking in Google’s skunkworks.
Models like Imagen are trained on a huge number of examples that are usually taken from public websites and datasets on the web. Many AI developers see training data as a competitive advantage and thus keep it and the information related to it close to the chest. But the details of the training data are also a potential source of intellectual property lawsuits, another disincentive to disclose much.
I asked, as I always do with announcements related to AI model creation, about the data used to train the updated Imagen 2 and whether creators whose work might have been scanned in the model training process would be able to opt out. at some future point.
Google only told me that its models are “primarily” trained on public web data, drawn from “blog posts, media transcripts, and public chat forums.” Which blogs, transcripts and forums? It’s anyone’s guess.
A spokesman pointed to Google’s web publisher controls that allow webmasters to prevent the company from removing data, including photos and artwork, from their sites. However, Google would not commit to releasing an opt-out tool, or alternatively to compensating creators for their (unwitting) contributions — a step many of its competitors have taken, including OpenAI, Stability AI and Adobe.
Another point worth mentioning: Images converted to live text are not covered by Google’s AI creation indemnity policy, which protects Vertex AI customers from copyright claims related to Google’s use of the training data and outputs of its AI output models. This is because images that are converted to live text are technically in preview. the policy only covers production AI products in general availability (GA).
Regression, or when a production model spits out a copy of an example (eg an image) it was trained on, is rightfully a concern for enterprise customers. Study both atypical and academic have shown that the first-generation Imagen was not immune to this, taking recognizable photos of people, copyrighted artists’ work, and more when asked in certain ways.
Barring controversy, technical issues, or some other major unforeseen setback, images converted to live text will enter GA somewhere down the line. But with live images as they exist today, Google is basically saying: use at your own risk.